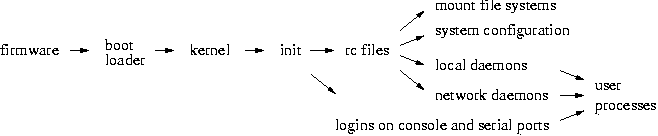
Figure 5.2: simplified process genealogy of a typical UNIX system.
In the last two chapters we looked at information that can be found in file systems. Such information is static in nature, and is typically examined after the fact. In this chapter we turn our attention from static data to the more dynamic world of running code, and look at system state in real time.
After an overview of the basic elements of computer system architecture, we walk through the system life cycle from start-up to shutdown, and present some measurements of the complexity of today's operating systems. We cannot fail to observe how this complexity introduces opportunities for subversion.
Before we turn to system subversion, we recapitulate the essential kernel and process concepts that are often involved with subversion. There is a lot more to kernels and processes than we can describe in the context of this book, and the interested reader is referred to any good book on UNIX and UNIX system administration [Nemeth, 2001].
Subversion is the subject of the second half of this chapter. We present the mechanisms behind several generations of so-called rootkit software, and show examples of their detection. This is an ongoing cat and mouse game of making observations, subversion of observations, and detection of subversion. And since none of the popular systems today can offer strong security guarantees, this cat and mouse game is likely to continue until a radical change is made to system architecture.
Over the past 30 years the basic architecture of computer systems has not changed significantly, despite major advances in hardware and in operating systems. The main principle that underlies this architecture is separation of concerns. We distinguish two main levels: process and system. At the process level, software runs in an environment that is relatively independent of hardware and operating system details. At the system level, hardware and software provide the environment in which processes execute. Within each level we distinguish some additional structure as shown in figure 5.1.
Process
Executable program
System library System
Operating system kernel
Hardware Figure 5.1. General relationship between hardware, operating system kernel, system libraries and executable program files.
Going from top to bottom we encounter the following layers:
The executable program. Each running instance of a program file runs in what appears to be its own virtual memory. Once a process starts execution it is usually linked with one or more run-time libraries as described next.
Libraries with standard utility routines. These routines run as part of the process that they are linked into. Library code provides generic services to application programs such as computing a square root, looking up an IP address, etc.
Resident operating system kernel (we'll use the term kernel although the implementation may use multiple cooperating processes). The kernel manipulates the hardware and provides an interface to processes in terms of files, directories, network connections, other processes, etc.
The hardware. This layer presents an interface in terms of memory pages, disk blocks, network packets, device registers, I/O ports, interrupts, etc. Beyond these low-level interfaces lies another universe of processors and operating systems that are embedded inside hardware. Regrettably, we won't be able to cover hardware-level forensics in this book.
The benefits of this architecture are portability and simplicity. Portability means that the exact same application software can be used on multiple versions of similar operating systems, and on multiple configurations of similar hardware. Simplicity means that processes do not have to be aware that they share one machine with other processes. The operating system deals with all the complexities of resource management, and the hardware does the work.
Having introduced the basic layers of the computer system architecture we now take a bottom-up approach from hardware to executable programs, and watch how different layers take control of the machine at different points in time. Figure 5.2 gives a simplified picture of the entire system start-up procedure.
When a computer system is powered up, resident firmware (often called BIOS, EEPROM, etc.) performs a hardware self test and some low-level configuration. This includes finding out the type and capacity of installed random-access memory, locating additional resident firmware in, for example, disk or network interface controllers, configuring plug-and-play devices, and so on. Meanwhile, intelligent peripherals may execute their own power-up self test and configuration sequences.
After completion of the power-up self test and low-level configuration, the resident firmware loads a boot program from disk or from the network, and gives it control over the machine. The boot program loads either the operating system kernel or the next stage boot program. Boot programs and operating system kernels often have their own configuration parameters as discussed in a later section.
The kernel probes the hardware for devices such as disk or network interface controllers and may load kernel modules to access and initialize those devices. Once the kernel completes its initialization, it creates the init process, and passes control to it. From this point onwards the kernel becomes dormant. Kernel code executes only in response to hardware interrupt events and in response to system call requests from processes.
Figure 5.2: simplified process genealogy of a typical UNIX system.
The init process executes the system startup and shutdown procedures. These procedures are implemented by a multitude of "rc" files (shell command files) that are usually located under the /etc or /sbin directory. The startup shell command files mount file systems, configure kernel modules and kernel parameters (more about those in a later section), configure network interfaces, and start daemon processes, including the window system that presents the graphical console login window. The init process also controls non-graphical logins via hard-wired and dial-up terminal ports. The shutdown shell command files stop specific processes in a controlled manner, before all the left-over processes are forcibly terminated.
An important function of init is to implement the so-called run levels. With BSD-like systems these are called single-user (administrative access only) and multi-user. Solaris and Linux run levels are called S (single user) and 0-6, where 0 and 6 are for system shutdown and 1-5 are for increasing levels of service. For example, different run levels may enable multi-user logins, network logins, graphical console logins, or file sharing; the exact details of run level functionality differ per system.
In order to get these numbers we recorded all file access requests by all init child processes in real time, including file accesses that happened while file systems were still mounted read-only. Tools that can monitor file access and other system call requests are discussed in chapter 6. Playing with system startup sequences is fraught with peril, especially when playing games with a critical process such as init. It was very easy to make a mistake that rendered the entire system unusable. Our measurements were possible thanks to VMware's virtualization software (see chapter 6). Whenever we made a mistake, we simply discarded all our changes to the file system and tried again.
System type and configuration Program files Other files Non-existent files RedHat 4.1 boot, no GUI 81 290 217 Redhat 5.2 boot, no GUI 86 494 289 Redhat 6.1 boot, no GUI 76 639 262 Redhat 6.1 boot and default GUI login/logout 107 1667 1090 Solaris 2.5.1 boot, no GUI 65 250 229 Solaris 7.0 boot, no GUI 77 344 273 Solaris 7.0 boot and default GUI login/logout 150 1153 1986 Table 5.1: Number of different file names accessed while booting generic Linux and Solaris systems, with and without a graphical user interface (GUI). The RedHat and Solaris counts include all accesses after init startup. Program files include executable files as well as run-time libraries and other files with executable machine code.
Two things stand out in the table. First is that the graphical user interface surpasses in complexity the entire system that it runs on. The second thing that stands out is the large number of requests involving non-existent pathnames. One source of non-existent pathnames is sloppiness in the form of default command PATH searches. A second source is a different form of sloppiness: many startup scripts probe the file system in order to find out what is installed. Finally, a major source of non-existent pathname lookups is the backwards compatibility support for legacy pathnames that are built into program and configuration files.
What the table does not show is the large numbers of attempts to access the same pathname repeatedly, regardless of whether the pathname exists. This is a symptom of inefficiency, and all the little inefficiencies together ensure that system startup times do not improve despite continual improvements in hardware performance.
Our little study shows that there exist literally hundreds if not thousands of opportunities to subvert the integrity of a system without changing any file: it is sufficient to add one extra file in an innocuous place so that it is accessed during, for example, system start-up. This kind of subversion can be prevented to some extent by requiring that files have valid digital signatures. At the time of writing, such features are still in the form of experimental add-ons for UNIX systems [van Doorn, 2001; Williams, 2002].
After the overview of architecture and system life cycle we now take a closer look at individual software layers of the system architecture. First we'll take a look at the kernel level. The purpose of the operating system kernel is to make computer hardware more useful to application programs, just like the purpose of application programs is to make computer systems more useful to human beings. While the application program interfaces provided by UNIX kernels and system libraries are relatively standardized by organizations such as ISO, IEEE and XOPEN, there can be large differences between kernel internals. We will focus on the common elements in the architecture of typical UNIX kernels as shown in figure 5.3.
process layer
system calls process
managementmemory
managementfile
systemsnetwork
protocolslow-level code and device drivers hardware layer Figure 5.3: Major subsystems of a typical UNIX kernel. The adjacent hardware and process architecture layers are shown for context.
When a machine is turned on, built-in firmware configures the hardware, and loads a boot program from disk, or from a network server. Depending on how powerful this boot program is, one or more additional boot programs may be needed to get the kernel up and running. The general sequence of events is described in the system manual pages: Solaris boot(1M), Linux boot(7), or FreeBSD boot(8). Boot programs are controlled by configuration parameters, and sometimes they configure initial kernel configuration parameter values. Although the bootstrapping stage represents only a minuscule portion of the system life cycle, its integrity is critical for the integrity of the entire system. For an implementation of secure booting in the IBM PC environment, see the work by Arbaugh and others [Arbaugh, 1997].
System Boot loader configuration Kernel file name Kernel configuration
Solaris /etc/bootrc (x86 platform)
firmware (sparc platform)/kernel/genunix /etc/system Linux /boot/grub/grub.conf
/boot/lilo.conf/boot/vmlinuz /etc/sysctl.conf FreeBSD /boot.config
/boot/loader.conf
/boot/loader.rc/kernel
/kernel/kernel/boot/device.hints
Table 5.2: Typical boot loader and initial kernel configuration information.
As is to be expected, there is great variation in the way kernels are configured. Linux and FreeBSD systems have a sysctl command that gives read/write access to kernel configuration parameters and other data; the Linux /proc pseudo file system also gives read/write access to a subset of those parameters and other data. Solaris has the ndd command for reading or writing parameters and other data that lives in the drivers that implement the IP protocol family, while other Solaris kernel parameters may be set at run time with the mdb or adb commands. Listing 5.1 shows only a few of the more than 700 kernel configuration parameters of a FreeBSD kernel.
freebsd50% sysctl -a kern.ostype: FreeBSD kern.osrelease: 5.0-RELEASE kern.osrevision: 199506 kern.version: FreeBSD 5.0-RELEASE #0: Thu Jan 16 22:16:53 GMT 2003 root@hollin.btc.adaptec.com:/usr/obj/usr/src/sys/GENERIC kern.maxvnodes: 4182 kern.maxproc: 532 kern.maxfiles: 1064 kern.argmax: 65536 kern.securelevel: 1 . . . 728 more lines omitted . . .Listing 5.1: Examples of FreeBSD kernel parameters.
Loadable kernel modules are chunks of executable code and data that can be assimilated into a running kernel at any point during its life cycle. Once a module is loaded, its code runs as part of the kernel. With monolithic kernels, this means the module's code has access to everything inside and outside the kernel. Kernel modules are used to implement functionality within all of the major kernel subsystems shown in figure 5.3: from device drivers, file systems, and network protocols, up to system calls that provide new features to processes. Modules are loaded while the kernel initializes, and under the control of init startup procedures. Table 5.3 shows typical commands to manipulate the status of loadable kernel modules.
System Commands Solaris modload modunload modinfo Linux insmod rmmod lsmod FreeBSD kldload kldunload kldstat Table 5.3: Typical commands to load, unload and query the status of loadable kernel modules.
Many UNIX systems have relatively monolithic kernels: most of the code is permanently linked into the kernel file, and only a handful modules are loaded dynamically. Solaris takes the opposite approach: more than a hundred modules are loaded dynamically. Even the process scheduler is loaded as a kernel module, as shown in listing 5.2.
solaris9% modinfo Id Loadaddr Size Info Rev Module Name 5 fe925000 3e92 1 1 specfs (filesystem for specfs) 7 fe92a275 2fda 1 1 TS (time sharing sched class) 8 fe92cdcb 888 - 1 TS_DPTBL (Time sharing dispatch table) 10 fe92ce43 208 - 1 pci_autoconfig (PCI BIOS interface 1.38) 11 fe92cfc7 27d6e 2 1 ufs (filesystem for ufs) . . . 100 lines omitted . . . 131 deeae12e ae4 23 1 ptm (Master streams driver 'ptm' 1.4) 132 fe9610f1 be4 24 1 pts (Slave Stream Pseudo Terminal dr) 133 feaa37b7 12ae 17 1 ptem (pty hardware emulator)Listing 5.2: Examples of Solaris 9 kernel modules (ix86 platform).
The convenience of loadable kernel modules also has a darker side. Because their code has access to everything inside and outside a monolithic kernel, they are also powerful tools in the hands of intruders. As we will see later, kernel modules exist for hiding traces of intrusion (including the intruder's kernel modules), and for controlling nearly invisible back doors that give privileged access to intruders. We will return to the issue of corruption and detection at the end of this chapter.
Many kernel configuration parameter settings affect the security of a system. One kernel configuration parameter of particular interest is the kernel security level. This is a standard feature on 4.4 BSD descendant systems, and is available as add-on feature for Linux. As the security level increases, functionality is reduced. The security level can be raised at any time with, for example, the sysctl command, but only the init process can lower the security level while the system is in single user mode. Table 5.4 summarizes the semantics as defined with 4.4BSD. Some systems support additional security levels and/or additional restrictions. For precise details, see the securelevel(7) manual page, or its equivalent.
Level Restrictions
-1 Permanently insecure mode. Always run the system in level 0 mode, and do not raise the security level when changing from single-user mode to multi-user mode. 0 Insecure mode, normally used while booting the system. There are no additional restrictions beyond the usual file and system call access controls. 1 Secure mode, normally used after the system switches to multi-user mode. Immutable and append-only file attributes may no longer be turned off, open for writing is no longer allowed with disk devices that contain mounted file systems, as well as memory devices, and kernel modules may no longer be loaded or unloaded. 2 Highly secure mode. Even unmounted disks may no longer be opened for writing.
Table 5.4: Typical 4.4BSD security level settings and restrictions.
These security features can be valuable for the protection of forensic information. An append-only flag protects logfiles against change of already written content, and an immutable flag protects a file against any change including renaming (although such protection means little when a parent directory can still be renamed). Disallowing open-to-write of disk devices protects file systems against tampering that would otherwise be hard to detect. And none of these measures would be effective unless write access is revoked to the kernel memory or main memory devices, because it would be trivial to turn off the protection offered by security levels.
The security level mechanism should not be confused with the discretionary or mandatory access control mechanisms that are built into many operating systems. The purpose of access control is to enforce a policy. The problem with policies is that they may be changed at any point in time by a suitably authorized process. The purpose of security levels, on the other hand, is to revoke access unconditionally; once a system enters security level 1, there is no mechanism that grants permission to load kernel modules or to write to raw memory or to mounted disk devices, except for returning the system to single-user mode or rebooting the system into a less secure configuration. Thus, security levels are not impenetrable, but they add a barrier against compromise that cannot be implemented with access control alone.
Each UNIX system comes with its own assortment of process and system status monitoring tools. Most tools look at one or two particular aspects of the system: process status, network status, input/output, and so on. Because of the large variation between tools and between systems we will introduce only a few representative tools and refer the reader to the system documentation for information about individual platforms. Process and system status tools can reveal signs of intruder activity such as files, processes or network connections. This makes them a prime target for subversion by intruders. We will discuss subversion of status tools later in the chapter.
The ps command is the basic process status tool. Many systems provide multiple implementations and/or user interfaces; the Linux version even has more than a dozen personalities. In our examples we use the BSD user interface because it provides information that is not available via some of the other user interfaces. Solaris has a BSD compatible ps command in /usr/ucb/ps.
By default, the ps command tries to produce nice output, but that means a lot of information is suppressed or truncated. For example, in order to see the entire command line of a process we need to specify one or more w options, and we need to specify the e option to display information in a process's environment. This is a list of name=value pairs that is inherited from the parent process. Linux and FreeBSD require super-user privileges in order to view environment information from other user's processes. Solaris currently does not impose this restriction.
A process environment may reveal whether the process was started in the regular manner or not. For example, system processes started at boot time tend to have few if any environment settings. If a system process such as inetd (the process that manages incoming connections for many common network services) was restarted by hand, then the environment could give away useful information such as the remote user's origin, working directory information, etc., as shown with the following command:
$ ps -aewww PID TT STAT TIME COMMAND . . . 6597 ?? Ss 0:00.01 PATH=/sbin:/bin:/usr/sbin:/usr/bin:/usr/game s:/usr/local/sbin:/usr/local/bin:/usr/X11R6/bin:/root/bin MAIL=/var/ma il/wietse BLOCKSIZE=K USER=wietse LOGNAME=wietse HOME=/root SHELL=/bin /csh SSH_CLIENT=168.100.189.2 841 22 SSH_TTY=/dev/ttyp0 TERM=xterm PWD =/home/wietse XNLSPATH=/usr/X11R6/lib/X11/nls XKEYSYMDB=/usr/X11R6/lib /X11/XKeysymDB XAUTHORITY=/home/wietse/.Xauthority /usr/sbin/inetd -wW . . .
The lsof (list open files) tool lists processes with all their open files, network ports, current directories, and other file system related information [Abell, 2004]. This very useful program brings together information that is often scattered across several different tools. Because the output can reveal a lot about what a process is doing, many lsof implementations give little or no information about processes that are owned by other users. To examine processes owned by other users, lsof needs to be invoked by the super-user.
Below is a typical sample of output for an OpenSSH server process that is waiting for connection requests. OpenSSH is an implementation of the SSH protocols for encrypted remote logins [OpenSSH, 2004].
# ps ax | grep sshd 186 ?? Is 0:01.17 /usr/sbin/sshd 39288 pb R+ 0:00.00 grep sshd # lsof -p 186 COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME sshd 186 root cwd VDIR 13,131072 512 2 / sshd 186 root rtd VDIR 13,131072 512 2 / sshd 186 root txt VREG 13,131072 198112 15795 /usr/sbin/sshd . . .10 run-time library object files omitted. . . sshd 186 root 0u VCHR 2,2 0t0 7955 /dev/null sshd 186 root 1u VCHR 2,2 0t0 7955 /dev/null sshd 186 root 2u VCHR 2,2 0t0 7955 /dev/null sshd 186 root 3u IPv6 0xd988e720 0t0 TCP *:ssh (LISTEN) sshd 186 root 4u IPv4 0xd988e500 0t0 TCP *:ssh (LISTEN)
In the output, cwd is the current directory, rtd the root directory which in this case is the regular file system root, txt is the executable file, and 0..4 are open files and sockets. For each entry, lsof gives additional information such as the type (directory, regular file, character special device, socket for IP version 4 or 6), and other identifying information such as the device and inode number or the address of the socket control block.
Of particular interest is the lsof -i option which shows all processes with active network ports. The output can reveal processes that aren't supposed to have open network connections, and that could be a sign of trouble. The example below shows a shell (command interpreter) process that is attached to TCP port 21. Normally, this port is used by FTP server processes to receive commands and to report status results. In the example, 10.1.2.3 is the address of the local machine, and 192.168.3.2 is the address of an attacking machine. Note: the -> arrow does not imply that the connection was initiated by the local machine; the lsof command has no information about which end of a connection is the client or server.
# lsof -ni COMMAND PID USER FD TYPE DEVICE NODE NAME . . . sh 39748 root 0u IPv4 0xd9892b60 TCP 10.1.2.3:21->192.168.3.2:1866 sh 39748 root 1u IPv4 0xd9892b60 TCP 10.1.2.3:21->192.168.3.2:1866 sh 39748 root 2u IPv4 0xd9892b60 TCP 10.1.2.3:21->192.168.3.2:1866 . . .
Output like this is a sure sign that someone exploited an FTP server vulnerability in order to spawn a shell process. These exploits are popular because the shell process inherits full system privileges from the FTP server process.
The findings of lsof can be checked against the findings of other tools that also look at process and/or file/network information, such as the netstat command. The following command shows the status of all network ports and of all network connections. We omit all but the connection that corresponds with the FTP server exploit.
# netstat -nf inet Active Internet connections Proto Recv-Q Send-Q Local Address Foreign Address (state) . . . tcp4 0 0 10.1.2.3.21 192.168.3.2.18668 ESTABLISHED . . .
With Linux systems one would specify netstat -n --inet for an equivalent result. Talking of Linux, its netstat command has the very useful -p option to display process ID and process name information.
As we see, there is significant overlap between tools. When only an individual tool is compromised, the output from other tools may reveal the inconsistency. This is why intruders often replace multiple system utilities as part of their cover-up operation. However, system status tools are not really independent. Ultimately, all tools rely on a common source of information, the kernel. When the kernel is compromised, all tools may fail, and other techniques are needed to expose the compromise. We will return to this at the end of the chapter.
All process and system status tools get their information from the running kernel. Historical UNIX systems made only a limited amount of process and system status information available via well-documented system calls. Most information was obtained by directly accessing poorly documented data structures in kernel memory via the /dev/kmem pseudo device.
Modern UNIX systems make some process and system information accessible via the /proc pseudo file system. Each process has a subdirectory /proc/pid that is named after the numerical process ID. Each subdirectory contains an assortment of pseudo files for different process attributes; table 5.5 gives a few examples. Specific details of the proc file system are described in the system manual: FreeBSD procfs(4), Linux proc(5), and Solaris proc(4).
With the /proc pseudo file system, process attributes are accessed by opening the corresponding pseudo file. Process status reporting tools read status information, and programs such as debuggers manipulate processes by writing and reading control information (debuggers are discussed in chapter 6). Linux and FreeBSD /proc files are mostly text based and can be accessed in meaningful ways with the cat or echo commands, while Solaris uses binary data structures that require specialized tools as described in the proc(1) manual page.
Process attribute Solaris FreeBSD Linux program file /proc/pid/object/a.out /proc/pid/file /proc/pid/exe process memory /proc/pid/as /proc/pid/mem /proc/pid/mem memory map /proc/pid/map /proc/pid/map /proc/pid/maps command line /proc/pid/psinfo /proc/pid/cmdline /proc/pid/cmdline Table 5.5: Examples of per-process entries in the /proc file system. The Solaris psinfo pseudo file contains most of the information that is needed by the ps (list processes) command.
Besides processes, Linux and FreeBSD make a limited amount of kernel status information available under /proc, while Solaris uses additional pseudo devices such as /dev/ip for network status and /dev/kstat for kernel statistics. This apparent chaos of lookup mechanisms is not a problem as long as you can depend on tools such as ps, netstat or lsof whose output is relatively system independent. It complicates life, however, when you need to write tools that attempt to bypass potentially compromised utilities.
Unfortunately, the accuracy of information from system status tools is limited. Some limitations are unavoidable because the tools look at information that is changing, such as memory usage or open files. Other limitations are less obvious, often accidental, and can complicate the interpretation of results. To illustrate this we will show some limitations in the way process status tools report process command line information.
As a first example, process status tools may produce incomplete command-line information. Although UNIX systems have generous limits on the length of command lines, how much of this can be recovered depends on the UNIX system implementation and on the tool being used. Table 5.6 shows typical limits for Solaris, RedHat Linux and FreeBSD systems on i386 type hardware. The NCARGS constant in the file <sys/param.h> defines the combined upper bound on the command line and process environment.
System NCARGS ps command line length limit FreeBSD 5.0 64 kbyte length truncated to 0 if > 10000 bytes Redhat 8.0 128 kbyte length truncated to 0 if > 4 kbytes Solaris 9 1 Mbyte /usr/ucb/ps: all information recoverable
/usr/bin/ps: length truncated to 80Table 5.6: Command line limitations in typical process status tools.
Another oddity is that a process may modify its own command line as displayed by ps. This is possible on systems such as FreeBSD, Linux, and Solaris, but with Solaris the changes are visible only if you invoke the BSD style /usr/ucb/ps command with the w option; this is probably more an artefact of implementation than the result of a deliberate decision. As an example, the Sendmail mail transfer agent routinely changes the command line in order to display the process state. Here is an example for RedHat 8.0 Linux that displays all sendmail related processes:
redhat80% ps ax | egrep 'COMMAND|sendmail' PID TTY STAT TIME COMMAND 604 ? S 0:00 sendmail: accepting connections 614 ? S 0:00 sendmail: Queue runner@01:00:00 for /var/spool/client
Finally, the process name (the first component of the command line array) can be different from the executable file name. Some ps implementations will display the executable file name in parentheses when it differs from the process name. And even if the process name equals the file name, one UNIX file can have any number of names, as described in chapter 3. A fine example of this is (again) the Sendmail program. This command is installed such that different hard links or symbolic links to the same program file have a different names. Each name serves a different purpose, even though all names ultimately refer to the same executable file.
Having discussed how process and system status tools work, where they get their information, and the origins of some of their limitations, we now turn to popular methods to subvert the findings of these tools.
As mentioned in the preceding sections, the results from process and system status tools are subject to subversion. In the sections that follow we discuss how systems are subverted, how subversion is hidden, and how subversion may be detected. We limit the discussion to the upper three layers of the system architecture: executable file, library and kernel. Detection of subversion at the hardware level is beyond the scope of this book.
In our discussion of software subversion we will look at a category of malware that is known by the name of "rootkit", and that became popular first by the middle 1990s. The name stands for a combination of malicious software (such as a network sniffer or an attack tool), back door software that gives access without having to break into the machine, together with a collection of modifications to system software that hide the rootkit and other traces of the intrusion.
What makes rootkits popular is that they automate the process of installation and hiding, making it quick and painless. Typically, a rootkit is installed after system security is breached with a procedure that is also highly automated. When a rootkit is found on a compromised machine then it is very well possible that the whole incident didn't involve human control at all. While the intruder was doing something else, the rootkit installed itself and announced the compromised machine as another victim machine via some IRC channel.
Command-level rootkits hide the presence of malware by making changes to system commands. This approach is based on a very simple principle: in order to suppress bad news, they silence the messenger of that news. Table 5.7 shows a list of typical command-level rootkit modifications. Depending on the specific type of malware involved, many rootkits make modifications in addition to those listed in the table.
Replaced commands Hidden information du, find, ls Malware configuration files and network sniffer logs pidof, ps, top Network sniffer and/or back door process netstat Network ports associated with malware ifconfig Network sniffing "enabled" status Table 5.7: Typical system utilities that are replaced by command-level rootkits, and the information that the replacements attempt to hide.
As intrusion technology has evolved over time, so have rootkits. The first rootkits came with network sniffers to collect user names and passwords (such as the esniff program), while later versions came with remotely controlled agents for distributed denial of service attacks (such as the T0rn rootkit).
Typical back door software is in the form of a modified login program, or a non-standard or modified network server for the finger or ssh service, or an inetd server that listens on a secret network port. The back door is typically enabled by entering a specific password, or by connecting from a specific network source port or IP address. These are, however, not the only types of back door in existence as we will see later.
In order to evade detection, early rootkits not only replaced system utility software but also erased records in system logfiles. Some rootkits even went to the effort of giving modified system utilities the same file time stamps and CRC (cyclic redundancy check) value as the original files. Later command-level rootkits don't bother and simply install modified programs that hide the presence of malware.
Regardless of these details, none of the changes compromise integrity of the kernel. Detection of command-level rootkit modifications is therefore relatively easy, as long as one uses a trusted copy of the system utilities. Here is a number of ways in which command-level rootkits can be discovered:
If a rootkit installs a back door server process that listens for connections, the network port will be visible to an external network port scanner. To avoid detection in this manner, some rootkits come with a non-listening back door server that is triggered by a sequence of packets with specific content or type. For example, a "raw" ICMP socket bypasses the TCP/IP protocol stack, and receives a copy of all ICMP datagrams, except those that the local kernel generates its own responses for [Stevens, 1997].
On many operating systems (but not Linux) the strings command will reveal the names of all directory entries, including hidden and/or deleted files. The fls command can do the same, with more accuracy, when applied to the disk device (fls is introduced in chapter 3). In fact, any tool that bypasses the file system can reveal information that is hidden by file system utilities, including the ils tool (also introduced in chapter 3). These techniques do not work with file systems that are mounted from a server.
Commands such as strings may reveal the presence of non-standard file names that are embedded in modified system utility programs. These files control the hiding of processes, network connections or files, and often have unusual names. An example is given below.
Although corrupted versions of ps and other utilities hide malware processes, those processes can still be found via, for example, the /proc file system, as we show in an example below.
Deleted login/logout records in the wtmp file leave behind holes (actually: sequences of null bytes) that can be detected with a program that understands the binary format of the file.
Although the ifconfig command reports that a network interface is not in network sniffer mode, it takes only a small C program to query the kernel directly for the interface status.
Although the malware executable file CRC checksums, as reported by the sum or cksum command, match those of the original system utility executable files, the modifications still show up unmistakably when one compares the outputs of a strong cryptographic hash such as MD5.
Last but not least, no files or modifications remain hidden when one examines (a low-level copy of) the file system on a trusted machine. All the hidden files and modifications will be visible in plain sight. Chapter 4 describes disk imaging and analysis in detail.
$ strings /bin/ls | grep / /lib/ld-linux.so.1 >/t[j/ /usr/local/share/locale /usr/src/.puta/.1file . . .five more lines omitted. . .
The file name /usr/src/.puta/.1file looks very suspicious. If we try to list the /usr/src/.puta directory, the ls command hides the name as we would expect:
$ cd /usr/src $ ls -a . .. linux linux-2.2.14 redhat
However, the directory name still shows up when we use the echo command, together with the .* wild-card expansion feature that is built into the command shell:
$ echo .* * . .. .puta linux linux-2.2.14 redhat
In the .puta/.1file rootkit configuration file we find a lengthy list of file and directory names that must remain hidden, because these contain the malware program files, configuration files and data files:
$ cat .puta/.1file .puta .t0rn .1proc .1addr xlogin . . .29 more lines omitted. . .
Just as we can detect modified file utilities by comparing their results against output from an unmodified tool, we can detect modified process status utilities by comparing their output against information from the /proc file system. Table 5.8 shows that the ps command is hiding a process with ID 153 (it also shows that /proc and ps disagree on whether "2" corresponds to a process, but that is a different issue).
Entries in /proc Output from "ps ax" 1 2 3 4 5 6 153 271 341 3561 ? S 0:06 init [3] 3 ? SW 0:00 (kupdate) 4 ? SW 0:00 (kpiod) 5 ? SW 0:00 (kswapd) 6 ? SW< 0:00 (mdrecoveryd) 271 ? S 0:00 /sbin/pump -i eth0 341 ? S 0:00 portmap 356 ? SW 0:00 (lockd)Table 5.8: Comparison of process information from the /proc file system and from the ps command.
The system utilities that were replaced by the rootkit do a good job of hiding process 153. It is not only censored by process status tools such as ps, it also does not show up with network status tools such as netstat. However, for reasons that we may never know, this rootkit does not replace the lsof command and therefore it can help to reveal the purpose of process 153:
# lsof -p 153 COMMAND PID USER FD TYPE DEVICE SIZE NODE NAME nscd 153 root cwd DIR 3,5 4096 2 / nscd 153 root rtd DIR 3,5 4096 2 / nscd 153 root txt REG 3,5 201552 35646 /usr/sbin/nscd . . . nscd 153 root 7u IPv4 177 TCP *:47017 (LISTEN) . . .
The file name /usr/sbin/nscd suggests that this is a system program, but comparison with uncompromised systems shows that this program is present only in later Linux versions. Connecting with telnet to TCP port 47017 on the local machine confirms that we are looking at a back door process. In this case, we are welcomed by the opening banner of what appears to be an SSH server. SSH is popular with legitimate and illegitimate users because it encrypts and protects network, making it immune to inspection and manipulation.
# telnet localhost 47017 Trying 127.0.0.1... Connected to rh62. Escape character is '^]'. SSH-1.5-1.2.27
Each rootkit differs slightly in its approach to hide the presence of malware, and therefore each rootkit needs a slightly different approach for detection. An example of software that automates the search for known rootkits is the chkrootkit toolkit [Murilo, 2003]. It runs on a dozen different UNIX platforms, and at the time of writing recognizes more than 50 different rootkits. Chkrootkit looks for deleted login/logout records, signatures of replaced system utilities, rootkit configuration files and directories, missing processes, and for signs of kernel level subversion. But that will be the topic of a later section.
Instead of replacing system utilities, rootkits can hide their existence by making changes at the next level down in the system architecture, the system run-time library. A good example of this is redirecting the open() and stat() calls. The purpose of these modifications is to fool file integrity checking software that examines executable file contents and attributes. By redirecting the open() and stat() calls to the original file, it will appear as if the file is still intact, while the execve() call executes the subverted file. For example, listing 5.3 shows how one could redirect the open() call in a typical Linux run-time library:
#include <errno.h> #include <syscall.h> #include <real_syscall.h> /* * Define a real_open() function to invoke the SYS_open system call. */ static real_syscall3(int, open, const char *, path, int, flags, int, mode) /* * Intercept the open() library call and redirect attempts to open * the file /bin/ls to the unmodified file /dev/.hide/ls. */ int open(const char *path, int flags, int mode) { if (strcmp(path, "/bin/ls") == 0) path = "/dev/.hide/ls"; return (real_open(path, flags, mode)); }Listing 5.3: Library-level backdoor to redirect specific open() system calls. The real_syscall3() macro, whose definition is too ugly to be shown here, is a slightly modified copy of the standard Linux _syscall3() macro. We use it to define our own real_open() function that invokes the SYS_open system call.
Would an MD5 hash reveal the library modification? Not necessarily. While the run-time linker uses the low-level open() system call when it accesses the modified library file, the md5sum command uses the fopen() library routine and can be still redirected to the unmodified library file.
To work around modifications at this level, rootkit detection tools need to carry their own trusted copy of the system library routines. However, such measures and countermeasures have become less relevant with the arrival of rootkits that make changes to the running kernel, and that are therefore much harder to circumvent. or detect.
As we have seen in the previous section, rootkit modifications to system utilities are easy to circumvent. As long as we have a copy of the unmodified utilities we can still find the malware files, processes, and network ports. In a similar manner, rootkit modifications to system library routines are easy to circumvent.
The game changes dramatically when modifications are moved from the process layer into the kernel layer. Compromised kernel code cannot be circumvented easily, because hardware memory protection prevents user processes from doing so. All accesses to kernel memory must be mediated by the kernel, whether it is compromised or not. And since the running kernel is the source of information for all file, process and network status tools, those tools may produce inaccurate results when the kernel is compromised. Despite all these handicaps, kernel-level modifications may still be detectable, as we will show at the end of the chapter.
Just like command-level rootkits, kernel-level rootkits are installed after the security of a system is compromised. Over time, different methods have been developed to inject rootkit code into a kernel.
Loading a kernel module into a running kernel. This technique uses officially documented interfaces, and is therefore easier to use than other techniques. For the same reason this technique is also easier to detect. Some rootkit implementations attempt to remove their module names from the external kernel symbol table (Solaris /dev/ksyms or Linux /proc/ksyms) and from internal kernel tables, and/or intercept system calls that report kernel module status information [Plaguez, 1998; Plasmoid, 1999; Pragmatic, 1999]. We give an example at the end of this chapter.
Injecting code into the memory of a running kernel that has no support for module loading. This involves writing new code to a piece of unused kernel memory via the /dev/kmem device, and activating the new code by redirecting, for example, a system call [ASR, 1996; Cesare, 1999; Sd, 2001].
Injecting code into the kernel file or into a kernel module file. These changes are persistent across reboot, but require that the system is rebooted in order to activate the subverted code [Jbtzhm, 2002; Truff, 2003].
The exact details of these methods are highly system dependent. Even the methods that use officially documented interfaces are likely to break with different versions of the same operating system. We refer the interested reader to the references.
The purpose of many kernel rootkits is to hide malware processes, files and network ports, and of course to hide itself. There are two sides to information hiding: the output side and the input side. On the output side, the kernel must censor the output from system calls that produce a list of processes, files, network ports, etc. On the input side, any attempt to manipulate a hidden process, file, network port, etc., must fail as if the object does not exist. In addition, rootkits may redirect system calls such as open() in order to subvert the operation of software that verifies the integrity of executable file content and attributes. Figure 5.4 shows the typical architecture of early kernel rootkit implementations.
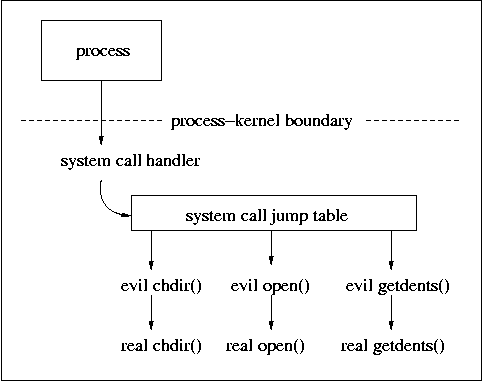
Figure 5.4: Rootkits based on system call interposition.
Early kernel rootkits subvert system calls close to the process-kernel boundary. In order to prevent access to a hidden file, process, etc., they redirect specific system calls to wrapper code that inspects the parameters and that decides whether the system call is allowed to happen. For example, code to subvert the open() system call goes like this:
evil_open(pathname, flags, mode)
if (some_magical test succeeds)
call real_open(pathname, flags, mode)
else
error: No such file or directory
To prevent rootkit disclosure, system calls that produce lists of files, processes, network ports or kernel modules are intercepted in order to suppress information that must remain hidden. For example, the code that subverts the getdents() system call (list directory entries) goes like this:
evil_getdents(handle, result)
call real_getdents(handle, result)
if (some_magical test fails)
remove hidden objects from result
The advantage of system call interposition is that the code is relatively easy to understand: the change is made at a point that is close to the user of those system calls. One drawback of this approach is that many system calls need to be intercepted. For example, in order to hide the existence of a file one would have to intercept all system calls that have a file name argument: open(), chdir(), unlink()and many others. That alone is some 40 system calls on Linux, FreeBSD and Solaris.
This drawback is addressed by subverting UNIX kernels at a level that is closer to the information that is being hidden. In the next example we will show how this can be used to hide files. Figure 5.5 shows the typical architecture of such subversion.
UNIX systems support a variety of file system types. Besides file systems with a UNIX origin such as UFS, EXT2FS, and EXT3FS, many systems support non-UNIX file systems such as FAT16, FAT32, NTFS, and others. Typically, each file system implements a common virtual file system (VFS) interface with operations to look up, open, or close a file, to read directory entries, and a dozen or so other operations [Kleiman, 1986].
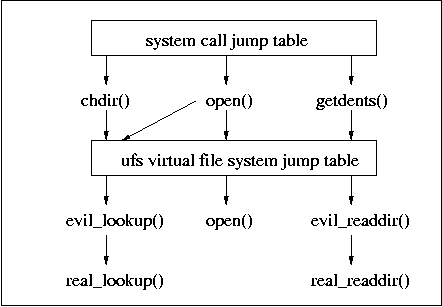
Figure 5.5: Rootkits based on interposition at object interfaces, showing subversion of multiple UFS file system methods.
Of all these virtual file system interface operations, the lookup operation is of particular interest. System calls that access an existing file or directory, etc., by name use the lookup operation to translate the pathname into the underlying file system object. By redirecting the lookup call at the virtual file system layer it is possible to hide a file from all system calls that access an existing file by name:
evil_lookup(parent_directory, pathname, ...)
if (some_magical test succeeds)
call real_lookup(parent_directory, pathname, ...)
else
error: No such file or directory
This modification is sufficient to hide an existing file from system calls that attempt to access it, such as chdir() or open(). However, it does not hide the file's existence from system calls that create a new directory entry, such as link(), mkdir(), socket(), mkfifo() and other system calls. Unless the malware is prepared to redirect names of new files that collide with names of hidden files, the system calls will fail with a "File exists" error. A rootkit detector that knows specific rootkit file names can exploit this property.
The kernel changes that we discussed sofar are relatively easy to detect, because they change code addresses in kernel tables that normally never change. We can examine these tables from outside the kernel by accessing /dev/kmem, or from inside the kernel with a forensic kernel module. An example follows in the next section.
Detection methods that look for changes in kernel tables can be defeated by leaving the tables alone, and by patching an existing kernel function so that it calls the malware. For an example of patching live kernel code, see [Cesare, 1999]. Such modifications can be found by inspecting all the running kernel code and by verifying all instructions against all kernel and kernel module files. This a non-trivial task, as the contents of modules change while they are linked into the kernel, in order to update references to external functions and data.
Kernel rootkits, like their non-kernel predecessors, may be exposed because they introduce little inconsistencies into a system. Some inconsistencies may show up externally, in the results from system calls that manipulate process, files, kernel modules, and other objects. Other inconsistencies show up only internally, in the contents of kernel data structures. Internal inconsistency is unavoidable, because every hidden process, file, or kernel module occupies some storage. That storage has to be claimed as "in use", and has to be referenced by something in the kernel's path of execution, even though the storage does not appear in kernel symbol tables. We will present examples of both types of inconsistency below.
As with command-level subversion, output from tools that bypass the file system can reveal information that is hidden by compromised file system code. Examples are ils and fls from the Coroner's Toolkit and Sleuth Kit, and even good the old strings command.
Even perfectly invisible kernel rootkits may give themselves away due to an oversight. For example, the modification time of an important system directory has changed, but there is no obvious change to the contents of that directory.
The results from process manipulating system calls and from the /proc file system should be consistent. If a process is being hidden then some system calls report "not found" while other system calls may not. The Checkps rootkit detector [Simpson, 2001] relies, among others, on such discrepancies; Chkrootkit also has tests for invisible processes. In an example below we will show a different approach to detect a hidden process.
Some kernel-based rootkits are controlled by invoking a legitimate system call with a special parameter value. For example, when the Adore rootkit is installed, setuid() (change process privileges) will report success for some parameter values even though the user does not have sufficient privilege; and when the Knark toolkit is installed, settimeofday() (set the system clock) will report success for some parameter values even though it should always fail when invoked by an unprivileged user. Magical numerical parameter values are easily detected by brute force: just try every possible value, and look at the system call result. Evasion of this detection method is easy, too: switch from a single call with a special parameter value to a sequence of calls with special parameter values, or use system calls with non-numerical parameter values.
The hard link count of a directory, as reported by the stat() system call, should equal the number of subdirectories, as reported by the getdents() system call. If a directory is being hidden, then it may show up as a missing hard link. This test is implemented by the chkdirs utility, part of the Chkrootkit rootkit detector.
Modifications to kernel tables such as the system call table or the virtual file system table may be detected after the fact by reading kernel memory via /dev/kmem, or by examining kernel memory from inside with a forensic kernel module such as Carbonite [Mandia, 2001]. We will show results from a /dev/kmem based tool in an example below.
Modifications to kernel tables etc. may also be detected as they happen, by a kernel intrusion detection module that samples critical data structures periodically and/or that looks for undesirable event sequences. An example of this category is StJude [STJUDE].
Modifications that hide files can show up as inconsistencies between information from the raw disk device and information returned by the kernel file system code. Likewise, modifications that hide network ports, processes, or kernel modules may be exposed by reading kernel memory and comparing the content of kernel data structures with results from system calls.
As an example of externally visible inconsistency we present a simple hidden process detection technique. The idea is to create a long sequence of processes. On UNIX systems that allocate PID (process ID) values sequentially, the sequence will show a hole where a PID is in use, or where a PID falls within a reserved range. As examples of the former, UNIX systems consider a PID as "in use" when it belongs to a running process, or when it belongs to a group of processes (either as a process group ID, or as its politically correct version, a POSIX session ID). As examples of reserved ranges, FreeBSD and Linux skip over the first 100 and 300 PID values, respectively, when the PID counter wraps around at its maximal value.
The hidden process search can be implemented with the somewhat slow Perl program shown in listing 5.4 that creates a sequence of child processes with the fork() system call. Whenever a hole appears in the sequence of child PID numbers, the program attempts to fill the hole with information about existing processes in /proc. In order to avoid false alarms due to short-lived processes that terminate before /proc can be searched, the program cycles twice through the entire PID range, which makes the program even slower.
#!/usr/bin/perl # checkpid - find hidden processes $last_pid = $PROCESS_ID; $first_pid = $last_pid + 1; for (;;) { # Fork a child processes and wait until the child terminates. if (($pid = fork()) < 0) { die "cannot fork: $!\n"; } if ($pid == 0) { exit; } wait; # Update the visible process list. Fill gaps in the PID sequence # with information from the /proc file system. $proc_seen[$pid] = 1; if ($last_pid + 1 < $pid - 1) { check_existing_processes(); } # Update the maximal process ID, and how many times we reached it. if ($pid > $max_pid) { $max_pid = $pid; } if ($last_pid > $pid) { $wrapped_around++; } $last_pid = $pid; # Report findings when we complete two passes over the PID range. if ($wrapped_around > 1 && $pid >= $first_pid) { print "Maximal PID: $max_pid\n"; for $pid (0..$max_pid) { report_missing($pid) if !$proc_seen[$pid]; } exit 0; } }Listing 5.4: A program that cycles through the process ID space and that recognizes hidden processes by the holes they leave behind.
The implementation of the check_existing_processes() function is system dependent and is omitted to save space; the complete script will be made available at the book website. When this program is run on a rootkit-infested Solaris system, it produces as output:
Maximal PID: 29999 Missing PID: 10257
The first line reports the highest process ID observed, and the second line reports a PID that was never observed as a process ID or as the ID of a process group or of a POSIX session. Indeed, ID 10257 corresponds to a hidden process that was set up in a lab environment in order to test this tool.
Due to the way the hidden process finding tool works, a positive signal should definitely be taken seriously. A negative result, on the other hand, would not mean that a system is clean. The rootkit might be too sophisticated for detection in this manner. Another limitation of the tool is that it cannot explore the reserved PID range (0-99 on BSD, 0-299 on Linux) and consequently will report those ranges as possibly hidden processes.
The findrootkit tool works in a very different manner. It examines kernel memory and can therefore give specific answers [Dik, 2004]. findrootkit is written in Perl, and uses the mdb low-level debugger to examine the running Solaris kernel via the /dev/kmem interface. The tool checks the consistency of information from multiple sources within and outside the kernel:
These consistency checks can reveal the presence of hidden kernel modules and other code that hides in the kernel. Additionally, the tool knows that specific kernel modules implement specific functions. For example, findrootkit knows the kernel modules that implement specific file systems or specific system calls. Tables 5.9a and 5.9b show an example of a kernel modification report.
Interposed vnode
operationInterposing
function
specfs:ioctl 0xfe9f23c8 procfs:lookup 0xfe9f2080 procfs:readdir 0xfe9f22fc ufs:setattr 0xfe9f1420 ufs:getattr 0xfe9f174c ufs:lookup 0xfe9f1a08 ufs:readdir 0xfe9f1d50 ufs:remove 0xfe9f1e30 ufs:rename 0xfe9f1eec
Interposed
system callInterposing
function
fork 0xfe9f2fb4 fork1 0xfe9f3058 kill 0xfe9f30fc sigqueue 0xfe9f31a4 exec 0xfe9f324c exece 0xfe9f3264
Tables 5.9a, 5.9b: Solaris rootkit kernel modification report, showing changes to the file system operations table, and to the system call jump table.
The report in tables 9a and 9b shows the findrootkit results for a Solaris kernel with a hidden kernel module. A number of file system operations and system calls is interposed, and is shown with the hexadecimal address of each interposing function. The kernel module name and interposing function names are unavailable, because those names were removed by the kernel module. The replacements in the proc file system are what one would expect for process hiding: the procfs:lookup() operation reporting that a hidden process does not exist, and the procfs:readdir() operation removing hidden processes from process listings. Numerous UFS (the default Solaris file system) operations have been modified for presumably nefarious purposes, as well as the specfs:ioctl() operation for the SPECFS file system, which provides access to device special files, to network sockets, and to other objects that exist outside the Solaris file system.
As with the previous tool, a sufficiently sophisticated rootkit can evade detection. In particular, tools like the last one that examine a kernel from outside can be fooled by subverting the /dev/ksyms and/or /dev/kmem drivers so that they lie about the contents of kernel memory. Even running the consistency checker inside the kernel would not make it immune to such tampering.
Writing this chapter has produced at least one good result: it has convinced its author to raise the BSD security level on critical machines. Although such protection can be subverted, it buys additional time, and forces an intruder to raise alarms.
The rootkits discussed in this chapter go through a lot of effort to hide processes or files, but there is no good reason why a rootkit should need to use processes or files in the first place. With some loss of convenience, backdoor software can be running entirely within the kernel, or at least the part of the backdoor that is memory resident. If storage space is needed there is plenty available in the mostly unused swap space, and the backdoor can be controlled via any number of local or networked covert channels. A rootkit that makes no persistent changes to the machine can be practically undetectable by software that runs within or above a compromised kernel. Finding it requires direct hardware access, or software that runs between the kernel and the hardware, such as a virtual machine monitor or hypervisor. At the time of writing, monitors and hypervisors are rarely used. And they are not the ultimate solution, either. They will have bugs, and therefore will be prone to subversion.
Although this chapter did not cover the possibilities for subversion at the hardware level, that does not mean that the authors are ignorant of its potential. Any writable storage presents an opportunity for subversion, especially when that storage is associated with, or is even part of, a processor of some kind. Hoglund and McGraw discuss this topic in a PC hardware specific context [Hoglund, 2004].
[Abell, 2004] The lsof (list open files) tool by Victor A.
Abell, 2004.
ftp://lsof.itap.purdue.edu/pub/tools/unix/lsof/
[Arbaugh, 1997] W. A. Arbaugh, D. J. Farber, J. M. Smith,
"A Secure and Reliable Bootstrap Architecture", Proceedings of the
1997 IEEE Symposium on Security and Privacy, pp. 6571, May 1997.
http://www.cs.umd.edu/~waa/pubs/oakland97.pdf
[ASR, 1996] Avalon Security Research, amodload kernel loader
for SunOS 4, 1996.
http://ftp.cerias.purdue.edu/pub/lists/best-of-security/110
[Cesare, 1999] Silvio Cesare, "Runtime kernel kmem patching",
1999.
http://reactor-core.org/runtime-kernel-patching/
[Dik, 2004] Casper H.S. Dik, private communication.
[van Doorn, 2001] L. van Doorn, G. Ballintijn, and W. A. Arbaugh,
"Design and implementation of signed executables for linux,"
University of Maryland, Tech. Rep. CS-TR-4259, June 2001.
http://www.cs.umd.edu/%7Ewaa/pubs/cs4259.ps
[Hoglund, 2004] Greg Hoglund, Gary McGraw, chapter 8 in "Exploiting Software". Addison Wesley, 2004.
[Jbtzhm, 2002] Jbtzhm, "Static Kernel Patching", Phrack 60,
2002.
http://www.phrack.org/show.php?p=60&a=8
[Kleiman, 1986] S.R. Kleiman, Vnodes: An Architecture for Multiple
File System Types in Sun UNIX", Summer 1986 Usenix Conference
Proceedings.
http://www.solarisinternals.com/si/reading/vnode.pdf
[Mandia, 2001] The Carbonite forensic software by Kevin Mandia
and Keith J. Jones, 2001.
http://www.foundstone.com/
[Murilo, 2003], The chkrootkit rootkit detection tool by Nelson
Murilo and Klaus Steding-Jessen, 2003.
http://www.chkrootkit.org/
[Nemeth, 2001] Evi Nemeth, Garth Snyder, Scott Seebass, Trent R. Hein, "UNIX System Adminstration Handbook", third edition. Prentice Hall PTR, 2001.
[OpenSSH, 2004] The OpenSSH remote connectivity software.
http://www.openssh.org/
[Plaguez, 1998] Plaguez, "Weakening the Linux Kernel", Phrack 52,
1998.
http://www.phrack.org/show.php?p=52&a=18
[Plasmoid, 1999] Plasmoid, "Solaris Loadable Kernel Modules", 1999.
http://www.thc.org/papers/slkm-1.0.html
[Pragmatic, 1999] Pragmatic, "Attacking FreeBSD with Kernel Modules",
1999.
http://www.thc.org/papers/bsdkern.html
[Sd, 2001] Sd, Dev, "Linux on-the-fly kernel patching without
LKM", Phrack 57, 2001.
http://www.phrack.org/show.php?p=58&a=7
[Simpson, 2001] The checkps rootkit detector by Duncan Simpson.
http://sourceforge.net/projects/checkps/
[Stevens, 1997] W. Richard Stevens, as cited in
the Raw IP Networking FAQ.
http://www.faqs.org/faqs/internet/tcp-ip/raw-ip-faq/
[StJude, 2002] The Saint Jude Kernel-Level IDS project.
http://sourceforge.net/projects/stjude/
[Truff, 2003] Truff, "Infecting loadable kernel modules", Phrack
61, 2003.
http://www.phrack.org/show.php?p=61&a=10
[Williams, 2002] Michael A. Williams, "Anti-Trojan and Trojan Detection
with In-Kernel Digital Signature testing of Executables".
http://www.trojanproof.org/