
Figure 1.1: Werner Heisenberg, Goettingen, 1924
Now, a few words on looking for things. When you go looking for something specific, your chances of finding it are very bad. Because, of all the things in the world, you're only looking for one of them. When you go looking for anything at all, your chances of finding it are very good. Because, of all the things in the world, you're sure to find some of them.A few years ago a friend sent out a cry for help. Someone broke into her Solaris computer system and deleted a large number of files. To help her out we wrote a first version of our file recovery tools that later became part of The Coroner's Toolkit [Farmer, 2004]. Our friend only wanted her files back, but we had a different agenda: we wanted to actually find out what happened.-- Darryl Zero, The Zero Effect
We did not expect to recover a lot of information intact. Solaris, like many UNIX systems, has no file undelete feature. The data from deleted files were lying on the disk as a giant puzzle, and we would have to put the pieces back together again. The UNIX FAQ was particularly pessimistic about our prospects [FAQ, 2004]:
For all intents and purposes, when you delete a file with "rm" it is gone. Once you "rm" a file, the system totally forgets which blocks scattered around the disk were part of your file. Even worse, the blocks from the file you just deleted are going to be the first ones taken and scribbled upon when the system needs more disk space.As we explored the destroyed file system we found that common wisdom was overly pessimistic. First, modern file systems do not scatter the contents of a file randomly over the disk. Instead, modern file systems are remarkably successful in avoiding file fragmentation, even after years of intensive use. Second, deleted file information can persist intact for a significant amount of time. You can read more on deleted file persistence in chapter 7.
The approach we followed is typical for how we advocate solving problems: rely on past experience, listen to advice from others, and use existing tools. But also don't be afraid to turn common wisdom into myth, to create your own tools, and to develop your own methodology when that is needed to crack a case. Otherwise, you may end up like the person who searches for lost keys under the street light because the light is better there. This is the central message of this book: if you want to learn to solve problems, you must be ready to look anywhere, for anything, and you must be prepared when you find it.
The remainder of this chapter is an introduction to the major concepts that we cover in this book. We do not expect that every reader will have the patience to read every chapter in sequence. You may use this chapter as a springboard to get to the topics that you're most interested in.
Oh, and lest we forget to mention this: our friend did get many of her files back.
The vast majority of files on two fairly typical web servers have not been used at all in the last year. Even on an extraordinarily heavily used (and extensively customized) Usenet news system less than ten percent of the files were used within the last 30 days. Whether they are programs and configuration files that are never used, or archives of mail, news, and data, etc., there are lots of files gathering electronic dust. Similar patterns emerge from Windows PCs and other desktop systems. We find that often over ninety percent of files haven't been touched in the past year.
www.things.org www.fish.com news.earthlink.net Over a year: 76.6% 75.9 10.9 6 months-year: 7.6 18.6 7.2 1-6 months: 9.3 0.7 72.2 Day-month: 3.6 3.1 7.4 Within 24 hrs: 2.9 1.7 2.3 Table 1.1: Percentage of files read or executed recently for a number of internet servers.
Why is this? Even a one MIPS (million instructions per second) machine could generate enough new data to fill a terabyte drive in a short time. Computers are busy enough, certainly, but most activity accesses the same data, programs, and other resources over and over again. As a system keeps running around accessing the same files again and again, it is quite literally stepping upon its own footprints. This is why footprints from unusual activity not only stand out, they are likely to stand out for a long time because most information on a system is rarely touched.
Almost every chapter in this book discusses digital footprints in one form or another. Examples of footprints in file systems are found in chapter 2, "Time machines" and chapter 4, "File system analysis". For a discussion of footprints in main memory, see chapter 8, "Beyond processes".
The forensic analysis of a system revolves around a cycle of data gathering and processing of the information gathered. The more accurate and complete the data, the better and more comprehensive the evaluation can be. The original data is safeguarded in a pristine state and any analysis should be performed on a copy of the computer's data. This is somewhat analogous to taping off a murder scene to prevent physical evidence being destroyed, which is done to preserve evidence, allow others to verify conclusions, and minimize data tampering.
Ideally you want an exact copy of the entire system and all its data, but there are roadblocks that prevent this. As you're collecting data other users or programs on the system may trigger changes in state or destroy valuable evidence. Intruders or miscreants may set electronic mines that might also damage data if agitated. And the mere execution of a program will disturb the computer's state as it loads and runs.
It's because of these sorts of problems that traditional forensic analysis has focused on data from systems that aren't running at all. Doctrine directs you to power off the system and copy the data that has survived the transition - program logs, access times, the content of files, etc. Analysis is then done on a copy of the data, which minimizes the danger to the original. This facilitates easy capturing of data and a reasonably non-repudiable chain of logic when demonstrating results.
Our general philosophy promotes greater understanding over higher levels of certainty, which could potentially make such methodology more suspect in a court of law. Paradoxically, however, the uncertainty - primarily in the data collection methods - can actually give a greater breadth of knowledge and more confidence in any conclusions that are drawn. This process requires consistent mechanisms for gathering data and a good understanding of any side effects of the same. We strongly believe to obtain dependable results automation is a is a near-necessity for gathering forensic data.
Certainly care and planning should be used when gathering information from a running system. Isolating the computer - from other users and the network - is the first step. And given that some types of data are less prone to being disturbed by data collection than others it's a good idea to capture information in accordance to its expected lifespan. The life expectancy of data varies tremendously, going from nanoseconds (or less) to years, but table 1.2 can be used as a rough guide.
Table 1.2: The expected lifespan of data.
Registers, peripheral memory, caches, etc. nanoseconds Main Memory nanoseconds Network state milliseconds Running processes seconds Disk minutes Floppies, backup media, etc. years CD-ROMs, printouts, etc. tens of years
Following this Order of Volatility (OOV) gives a greater chance to preserve the more ephemeral details that mere data collection can destroy, and allows you to capture data about the incident in question, rather than simply seizing the side effects of your data gathering session! Of course this is all dependent on the situation - if all you're interested in is the contents of a disk, or evidence from an event that transpired long ago, there might be little point to capturing the memory the computer in question.
Is there any limit to what you can gather? Why not capture all the data, all at once? Unfortunately it is not possible to record changes to processes and files accurately in real time, for as you capture data in one part of the computer you're changing data in another.
| Almost a century ago, Werner Heisenberg (see figure 1.1) formulated one of the great principles of quantum physics, which describes the behavior of particles at atomic and smaller scales: one can accurately determine the position of a particle OR one can accurately determine its motion, but one cannot determine both accurately at the same time. |
Figure 1.1: Werner Heisenberg, Goettingen, 1924 |
The Heisenberg Uncertainty Principle is directly applicable to data gathering on a computer. It's not simply difficult to gather all the information on a computer, it is essentially impossible1. We dub this the Heisenberg principle of data gathering and system analysis.
Footnote 1. Virtual machines may be used to capture activity down to the actual machine code instructions [Dunlap, 2002], but on a practical level this is not possible on general-purpose computers and all their peripherals.
Nevertheless on a realistic level it isn't Heisenberg that is the main problem of capturing all the data on a computer. Computers aren't defined by their state at any given time, but over a continuum. Memory, processes and files can change so rapidly that recording even the bulk of those fluctuations in an accurate and timely fashion is not possible without dramatically disturbing the operation of a typical computer system.
Take the humble date program, which prints the current date and time, as an example. If we monitor it with strace, a program that traces a program as it runs, date executes over 100 system calls in a fraction of a second (including those to get the time, check the timezone you're in, print out the result, etc.) If we went further and monitored the machine code that the CPU executes in performing this work we would have many thousands pieces of information to consider. But even instrumenting all the programs on a computer doesn't tell the whole story, for the computer's video card, disk controller, and other peripherals each have their own tale to tell, with memory, processors, and storage of their own.
We can never truly recover the past. But we will show that you don't need all the data to draw reasonable conclusions about what happened.
About 70 years ago, Rene Magritte [Magritte, 2004] made a series of paintings that dealt with the treachery of images. The cover of this book shows an image of a pipe with the words "ceci n'est pas une pipe" (this is not a pipe) below. Yes, this is not a pipe - it's only a painting of a pipe. The image could be an artist's rendering of a real pipe, but it could also be completely imaginary one or a composite picture of many pipes. You can't tell the difference by simply looking at the image.
Computer systems are subject to the treachery of images as well. The image on your computer screen is not a computer file - it's only an image on a computer screen. Images of files, processes and network connections are only remotely related to the raw bits in memory, in network packets, or on disks. The images that you see are produced by layer upon layer of hardware and software. When an intruder "owns" a machine, any of those layers could be tampered with. Application software can lie, operating system kernels can lie, and even the firmware inside hard disk drives can lie.
Computer file systems, for instance, typically store files as sequences of bytes, and organize files within a directory hierarchy. In addition to names and contents, files and directories have attributes such as ownership, access permissions, time of last modification, and so on.
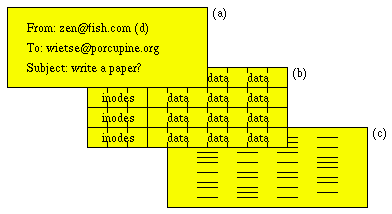
Figure 1.2: Simplified picture of files as seen by (a) users and applications, (b) file system software in the operating system, (c) hardware.
The perception of files and directories with attributes is one of the illusions that computer systems create for us, just like the underlying illusion of data blocks and metadata (inode) blocks. In reality, computer file systems allocate space from a linear array of equal-size disk blocks, and reserve some of that storage capacity for their own purposes. However, the illusion of files and of directories with attributes is much more useful for application programs and their users.
Even the notion of linear array of equal-sized disk blocks is an illusion. Real disks have heads and platters. They store information as magnetic domains and also reserve some of the storage capacity for their own purposes. The illusion of a linear sequence of equal-sized disk blocks has only one purpose: to make the implementation of file systems easier.
As we peel away layer after layer of illusions, information becomes more and more accurate because it has undergone less and less processing. As we descend closer and closer towards the level of raw bits, the information becomes less meaningful because we know less and less about its purpose. This issue of ambiguity versus accuracy is just one consequence of layering; in a later section we will see how it affects the persistence of deleted information.
In the early days of computing, the mathematician Alan Turing [Turing, 1950] devised a test for machine intelligence. The test was to be carried out as an interview via teleprinters, the predecessors of today's computer displays. An interviewer would ask the subject questions without knowing whether the answers came from a machine or from a human being. If the replies from a machine were indistinguishable from replies from a real human being then the machine must be considered as intelligent as a real human being.
Forensic computer analysis has strong parallels with the Turing test. You examine information from a computer system, and you try to draw conclusions from that information. But how do you know that the information can be trusted? Are you really looking at traces of what happened on a machine, or are you looking at something that the intruder wants you to believe? This is the Turing test of computer forensic analysis.
In order to avoid falling into a trap that was set up by an intruder, you have to carefully examine every bit of available information, looking for possible inconsistencies that might give away a cover-up attempt. The more sources of information you have, and the more independent those sources are from each other, the more confident you can be about your conclusions.
Listing 1.1 illustrates this process with a small example that uses the logging from typical UNIX systems. The figure shows information about a login session from three different sources: TCP Wrapper logging [Venema, 1992], login accounting and process accounting. Each source of information is shown at a different indentation level. Time proceeds from top to bottom.
Going from the outer indentation level inwards:May 25 10:12:46 spike telnetd[13626]: connect from hades | | wietse ttyp1 hades Thu May 25 10:12 - 10:13 (00:00) | | | | hostname wietse ttyp1 0.00 secs Thu May 25 10:12 | | sed wietse ttyp1 0.00 secs Thu May 25 10:12 | | stty wietse ttyp1 0.00 secs Thu May 25 10:12 | | mesg wietse ttyp1 0.00 secs Thu May 25 10:12 . . . . . . . . . . . | | ls wietse ttyp1 0.00 secs Thu May 25 10:13 | | w wietse ttyp1 0.00 secs Thu May 25 10:13 | | csh wietse ttyp1 0.03 secs Thu May 25 10:12 | | telnetd root __ 0.00 secs Thu May 25 10:12 | | | wietse ttyp1 hades Thu May 25 10:12 - 10:13 (00:00)Listing 1.1. Three sources of information about a login session.
The records in the example give a consistent picture: someone connects to a machine, logs in, executes a few commands, and goes away. This is the kind of logging that one should expect to find for login sessions. Each record by itself does not prove that an event actually happened. Nor does the absence of a record prove that something didn't happen. But when the picture is consistent across multiple sources of information it becomes more and more plausible that someone logged into Wietse's account at the indicated time.
In real life, login sessions leave behind more information than is shown in the example. Some of that information can be found on the target machine itself. Each command executed may change access and modification times of files and directories. Other information can be found outside the target machine, such as accounting records from network routers, event records from intrusion detection systems, forensic information on the host that originated the login session, and so on. All that information should properly correlate with each other. Information is power, and when you are investigating an incident, you just can't have too much of it.
Destroying information turns out to be surprisingly difficult [Gutmann, 1996] and [Gutmann, 2001]. Memory chips can be read even after a machine is turned off. Although designed to only read ones and zeroes, memory chips have undocumented diagnostic modes that allow access to tiny left-over fragments of bits. Data on a magnetic disk can be recovered even after it is overwritten multiple times. Although disk drives are designed to only read the ones and zeroes that were written last, traces of older magnetic patterns still exist on the physical media [Veeco, 2004].
The challenge of electronic dumpster diving is to recover information that is partially destroyed, that is, to make sense of digital trash. Without assistance from the application that created a file, it can be difficult to make sense of that file's content. And without assistance from a file system, disk blocks are no longer grouped together into files, so that data reconstruction can be like solving a puzzle. As more and more layers of illusion are affected by data destruction, the remaining information becomes more and more difficult to understand.
Once deleted, file content does not generally change until it is overwritten by a new file. On file systems with good data clustering properties, deleted files can remain intact for years. Deleted file information is like a fossil - its skeleton may be missing a bone here or there, but the fossil remains, unchanged, until it is completely overwritten.
The layering of illusions has major consequences for data destruction and data recovery. Deleting a file from the file system is relatively easy, but is not sufficient to destroy its contents or attributes. Information about the deleted file persists in disk blocks that were once allocated to that file.
This phenomenon of deletion and persistence can happen at other abstraction levels as well. At the abstraction level of magnetic disk reading heads, overwritten information persists as analog modulations on the newer information. And at the abstraction level of magnetic domains, overwritten information persists as magnetic patterns on the side of magnetic tracks.
At each layer in the hierarchy of abstractions that make up computer systems, information becomes frozen when it is deleted. Although deleted information becomes more and more ambiguous as we descend to lower and lower levels of abstraction, we also find that deleted information becomes more and more persistent. Volatility is an artefact of the abstractions that make computer systems useful. What we see is nothing less than OOV (order of volatility) in another guise with a host of implications of its own. You can find more on this in chapter 7, "Persistence of deleted file information".
Over time, computer systems have become more and more complex. As seen by the user, systems become increasingly mature and stable. Under the surface, however, computer systems have become less and less predictable in when and where they store information, and in how they recycle storage space. The information that we find on a disk, in main memory, or in network packets is affected by a multitude of processes that have trashed each other's footsteps and fingerprints.
Traditionally, these less predictable processes have been ignored by computer forensics. This book breaks with tradition and tries to learn from the way that systems manage information. As always, the challenge is to turn an apparent disadvantage, non-predictability, into an advantage. While trying to get a grasp on this problem we found the following real-world parallel helpful:
Table 1.3: The differences between digital archeology and geology.
Archaeology is about the direct effects from human activity, such as artefacts that are left behind. Digital archaeology is about the direct effects from user activity, such as file contents, file access time stamps, information from deleted files, and network flow logs. Geology is about autonomous processes that humans have no direct control over such as glaciers, plate tectonics, volcanism and erosion. Digital geology is about autonomous processes that users have no direct control over, such as the allocation and recycling of disk blocks, file ID numbers, memory pages or process ID numbers.
Just as real-world geological processes are constantly destroying archaeological sites, their cyberspace versions are constantly destroying information. For example, users have direct control over the content of existing files; after a file is deleted, users have no direct control over the sequence of destruction. We explore these processes further in chapter 7, "Persistence of deleted file information", and in chapter 8, "Beyond processes", which discusses the decay of information in main memory.
Destruction of information is not the only way that user control and autonomous processes interfere with each other. Autonomous processes also leave their distinguished mark when information is created. As we discuss in chapter 5, "Systems and subversion", most systems assign their process ID numbers sequentially. Some processes are permanent, and are created while the system boots up; these processes end up with relatively small process ID numbers. Most processes, however, are of a transient nature; they are created and destroyed throughout the life of a computer system. When a process records an event of interest to a logfile, the record typically includes a time stamp and the process ID number. These logfile records form a time series of process ID numbers, and gaps in this progression reveal that other processes were created in the mean time, even if we know nothing else about those processes. Figure 1.3 illustrates this.
Just as gaps in observed process ID sequences can reveal the existence of unobserved processes, similar indirect effects reveal unobserved events in file systems and in network protocols. Chapter 4, "File system analysis", shows how file ID number analysis can reveal information about the origin of a backdoor program file. Indirect effects also happen with network protocols. For example, the ID field in Internet packets is usually incremented by 1 for each packet generated by a system. By probing a system repeatedly over the network, you can find out how many other packets that system is generating, even when you can't observe those other packets directly [Antirez, 1998].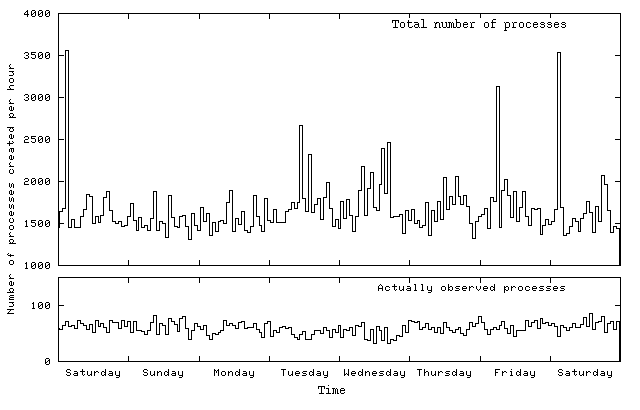
Figure 1.3: Total process creation rate (above) and actually observed rate (below) for a small FreeBSD mail server. The two peaks at 02:00 on Saturday morning are caused by a weekly housekeeping job.
Interesting phenomena happen on the boundary between autonomous processes and user-controlled processes. While digital archaeology is concerned with the direct, or first-order, effects of user activity such as processes, network connections and files, digital geology can reveal indirect, or second-order, effects from user activity on where information is stored, and on what file ID, process ID or network packet ID number is assigned to it.
First-order and second-order effects are just another consequence of the layered architecture of computer systems. Direct user control is limited to the upper layers of processes, files and network connections. Activity at lower layers becomes increasingly autonomous. This book looks mainly at first-order effects that happen close to the upper layer. Higher-order effects are still waiting to be discovered at the boundaries between lower layers.
[Antirez, 1998] Salvatore Sanfilippo (Antirez), BUGTRAQ mailing list
posting, December 1998.
http://www.kyuzz.org/antirez/papers.html
[FAQ, 2004] The UNIX FAQ, which currently resides at:
http://www.faqs.org/faqs/unix-faq/faq/
[Farmer, 2004] The Coroner's Toolkit by Dan Farmer and Wietse
Venema,
http://www.fish2.com/tct/
http://www.porcupine.org/tct/
[Gutmann, 1996] Peter Gutmann, "Secure Deletion
of Data from Magnetic and Solid-State Memory", Sixth USENIX
Security Symposium Proceedings, San Jose, California, July 22-25,
1996.
http://www.cs.auckland.ac.nz/~pgut001/pubs/secure_del.html
[Gutmann, 2001] Peter Gutmann, "Data Remanence in Semiconductor Devices", 10th USENIX Security Symposium, Washington, D.C., August 13-17, 2001.
[Magritte, 2004] Some information about Rene
Magritte's work can be found on-line at
http://www.magritte.com/
[Dunlap, 2002] George W. Dunlap, Samuel T. King, Sukru Cinar,
Murtaza Basrai, and Peter M. Chen, "ReVirt: Enabling Intrusion
Analysis through Virtual-Machine Logging and Replay", Proceedings
of the 2002 Symposium on Operating Systems Design and Implementation
(OSDI) , December 2002.
http://www.eecs.umich.edu/CoVirt/papers/.
[Turing, 1950] Alan M. Turing, "Computing Machinery and Intelligence", Mind, Vol. 59, No. 236, 1950. pp. 433-460.
[VEECO, 2004] Veeco Products. You can find images of
semiconductors and magnetic patterns on-line at:
http://www.veeco.com/
[Venema, 1992] Wietse Venema, "TCP Wrapper, network monitoring,
access control and booby traps", UNIX Security Symposium III
Proceedings (Baltimore), September 1992.
ftp://ftp.porcupine.org/pub/security/tcp_wrapper.ps.Z